

Não é teoria chata.
Não é definição decorada de livro.
É vida real. É produção. É pressão. 😅🔥
São aquelas perguntas que aparecem quando o sistema cai, o log começa a gritar e todo mundo olha pra você.
Se você está se preparando para entrevistas em empresas grandes, fintechs ou ambientes de alta escala… esse conteúdo é pra você.
Porque em entrevista de verdade, ninguém quer saber só:
“O que é
@RestController?”
Isso qualquer um responde.
O que eles realmente perguntam é:
“Sua API começou a falhar em produção sob alta carga. O que você verifica primeiro?”
Ou pior:
“O banco está lento, o CPU subiu e o cliente está reclamando. E agora?”
É aqui que o jogo muda. 🎯
É aqui que separa quem só estudou de quem está pronto pra sentar na cadeira de produção.
Se você quer pensar como engenheiro de verdade…
Se quer responder como quem já viveu o problema…
Então bora elevar o nível.
Vamos mergulhar em cenários reais de entrevista com Java & Spring Boot.
1️⃣ Cenário Java: Por que HashMap não é Thread Safe?
🔹 Pergunta:
Em produção, múltiplas threads estão atualizando um HashMap e dados estão sendo perdidos. Por quê?
💡 Explicação real:
HashMap não é sincronizado. Se múltiplas threads modificarem ao mesmo tempo, pode causar:
- Inconsistência de dados
- Loops infinitos (em versões antigas do Java)
- Perda de atualizações
✅ Correção em produção:
Use:
ConcurrentHashMap- ou
Collections.synchronizedMap()
Map<String, String> map = new ConcurrentHashMap<>();🎯 O entrevistador quer saber:
- Se você entende concorrência
- Se conhece alternativas seguras para produção
2️⃣ Cenário Spring Boot: API lenta em produção
🔹 Pergunta:
Sua API REST funciona bem localmente, mas está lenta em produção. O que você verifica?
💡 Checklist real em produção:
- Queries no banco (faltam índices?)
- Problema de N+1 no JPA
- Thread pool esgotado
- Latência de API externa
- Logs em nível muito alto
✅ Exemplo clássico: problema de N+1
Se você usa:
@OneToMany(fetch = FetchType.LAZY)🔥 Solução:
Use na FETCH na query:
@Query("SELECT o FROM Order o JOIN FETCH o.items")🎯 O entrevistador quer saber:
- Sua capacidade de debugging
- Seu conhecimento de banco + JPA
- Sua mentalidade de mundo real
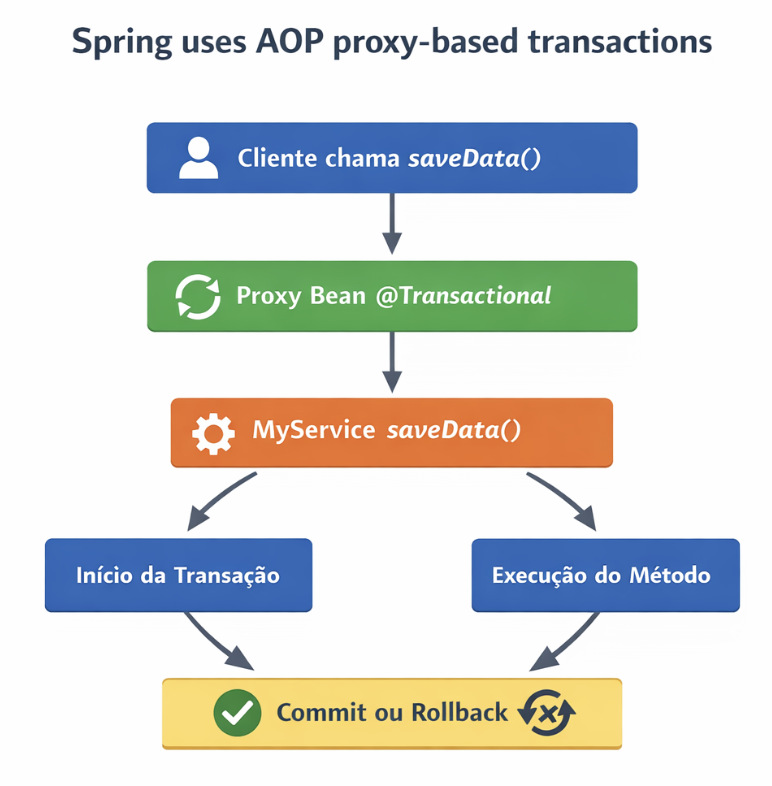
3️⃣ Cenário: Problemas com @Transactional
🔹 Pergunta:
Por que @Transactional às vezes não funciona?
💡 Motivos reais:
- Método chamado dentro da mesma classe
- Proxy não é acionado
- Exceção não é propagada
Spring usa transações baseadas em proxy AOP (Programação Orientada a Aspectos)

4️⃣ Cenário: Memory Leak em produção
🔹 Pergunta:
A memória do servidor aumenta continuamente. O que pode ser?
💡 Possíveis causas:
- Coleções estáticas
- Conexões não fechadas
- Cache de objetos grandes
- Uso incorreto de ThreadLocal
Ferramentas reais:
- JVisualVM
- Análise de heap dump
- Actuator metrics
5️⃣ Tratamento global de exceções na API
🔹 Pergunta:
Queremos respostas de erro consistentes. Como implementar?
✅ Solução:
- Usar @RestControllerAdvice
- Criar handlers globais
Empresas esperam:
- Estrutura de erro adequada
- Códigos personalizados
- Integração com logs
6️⃣ Falha de comunicação entre microservices
🔹 Pergunta:
Chamadas entre serviços falham intermitentemente. O que fazer?
💡 Abordagem:
- Configurar timeout
- Habilitar retry
- Usar Circuit Breaker
Ferramentas comuns:
- Resilience4j
- Spring Cloud Gateway
7️⃣ Pool de conexões esgotado
🔹 Pergunta:
Erro “Cannot get JDBC connection”. Por quê?
💡 Causas:
- Queries longas
- Conexões não fechadas
- Pool pequeno
Spring Boot usa HikariCP por padrão.
É necessário ajustar o tamanho do pool.
8️⃣ Segurança em produção
🔹 Pergunta:
Como proteger APIs REST?
Resposta real:
- Autenticação JWT
- Autorização baseada em roles
- HTTPS
- Configuração de CORS
- Rate limiting
9️⃣ Dependência circular
🔹 Pergunta:
Erro BeanCurrentlyInCreationException. Por quê?
💡 Causa:
Dois serviços dependem um do outro.
Correção:
- Usar injeção via construtor
- Refatorar lógica
- @Lazy como solução temporária
O entrevistador quer ver:
Entendimento do container IoC e do grafo de dependências.
🔟 Funciona local, falha em produção
🔹 Pergunta:
Por que funciona localmente mas não após deploy?
💡 Motivos comuns:
- Profiles diferentes
- Variáveis de ambiente ausentes
- Schema de banco diferente
- Timezone diferente
Boa prática:
Separar application-dev.yml e application-prod.yml.
1️⃣1️⃣ Consulta de grande volume de dados
🔹 Pergunta:
Como lidar com 1 milhão de registros?
❌ Errado: findAll()
✅ Correto:
- Paginação
- Streaming
- Processamento em batch
1️⃣2️⃣ Idempotência em sistema de pagamento
🔹 Pergunta:
Como evitar pagamento duplicado?
💡 Solução:
- Idempotency key
- Constraint única no banco
- Validação de token
1️⃣3️⃣ Estratégia de cache
🔹 Pergunta:
Como reduzir carga no banco?
💡 Resposta:
- Redis
- Spring Cache
- Estratégia de expiração (eviction)
O entrevistador observa:
Se você entende invalidação de cache — o problema mais difícil do software 😉
1️⃣4️⃣ Lidando com 10.000 requisições por segundo
🔹 Pergunta:
Como escalar sua aplicação?
💡 Resposta real:
- Escala horizontal
- Load balancer
- Ajuste de thread pool
- Processamento assíncrono
- Docker + Kubernetes
1️⃣5️⃣ Graceful shutdown
🔹 Pergunta:
Como evitar perder requisições durante deploy?
Use shutdown graceful para esperar requisições ativas terminarem.
1️⃣6️⃣ Transações distribuídas
🔹 Pergunta:
Como gerenciar transações entre microservices?
💡 Soluções:
- Saga Pattern
- Arquitetura orientada a eventos
- Filas de mensagem
Evitar 2PC em microservices.
1️⃣7️⃣ Estratégia de logs
🔹 Pergunta:
Como os logs devem ser projetados?
💡 Boas práticas:
- Logs estruturados (JSON)
- Correlation ID
- Logging centralizado (ELK, Splunk)
1️⃣8️⃣ Race condition
🔹 Pergunta:
Dois usuários reservam o último assento ao mesmo tempo. O que acontece?
💡 Correção:
- Lock otimista
- Lock pessimista
- Controle via banco (mais forte)
1️⃣9️⃣ Versionamento de API
🔹 Pergunta:
Como gerenciar versões da API?
💡 Abordagens:
- Via URL (/api/v1/users)
- Via header
Produção geralmente prefere URL por simplicidade.
2️⃣0️⃣ Upload de arquivos
🔹 Pergunta:
Como lidar com uploads grandes?
💡 Boas práticas:
- Não armazenar arquivo no banco
- Usar storage em nuvem
- Salvar apenas metadados no banco
- Validar tamanho e tipo
2️⃣1️⃣ Deadlock no banco
🔹 Pergunta:
O que causa deadlock e como corrigir?
💡 Causas:
- Atualizar linhas em ordem diferente
- Transações longas
Correção:
- Reduzir escopo da transação
- Ordem consistente de lock
- Lógica de retry
2️⃣2️⃣ Integração com fila de mensagens
🔹 Pergunta:
Por que usar Kafka ou RabbitMQ?
💡 Motivos:
- Desacoplamento
- Processamento assíncrono
- Alto throughput
Muito usado em fintech e e-commerce.
2️⃣3️⃣ Health checks
🔹 Pergunta:
Como monitorar microservices?
Usar Spring Boot Actuator:
- /actuator/health
- /actuator/metrics
🎯 Estratégia final para entrevistas avançadas
Quando perguntarem sobre chamadas desnecessárias ou problemas de performance… não responda assim:
“Usamos Redis para cache.”
Isso é ferramenta.
Ferramenta qualquer um cita.
Responda assim:
“Identificamos alta latência no banco sob carga elevada de leitura em produção. Introduzimos cache com TTL de 10 minutos e reduzimos o tempo de resposta em 65%, além de aliviar a pressão no banco.”
Percebe a diferença?
Você mostrou:
- 🔍 Diagnóstico
- 🧠 Tomada de decisão
- 📊 Métrica real
- 💡 Impacto no negócio
Isso não é resposta de quem estudou.
É resposta de quem resolve problema.
Isso é nível sênior. 🚀
About the Author

